연구실 과제와 관련하여 문헌 분석을 위해 관련 논문을 읽고 있다. 이번 게시물에서는 여러 방법을 이용한 증강 수행 후 CNN 기반 표적 인식 향상 방법을 정리해보려 한다. 해당 논문 내에 CNN과 SVM의 성능 비교 결과도 제시되어 있지만 SVM의 내용은 제외하겠다.
Introduction
SAR 표적 인식 성능을 향상시키는 다양한 방법들이 제안되었지만 영상 내의 표적이 이동하거나 스펙클 노이즈 강도의 변화, 각도 및 방향이 변경될 때 등의 어려운 조건에서는 인식 성능이 여전히 좋지 않다. 그래서 이 논문에서는 SAR 영상의 표적 인식에서 세 가지 유형에 대해 데이터를 증강한 후 훈련된 CNN을 사용함으로써 향상된 성능을 얻고자 한다.
CNN 모델 구조는 생략하겠다.
SAR 표적 인식을 위한 데이터 증강
A. Translation

CNN 구조에서의 Convolution 연산은 영상 내에서 작은 크기의 필터를 슬라이딩 시키며 적용되어 Local 영역에 대한 정보를 인식하기 때문에 작은 스케링의 이미지내 이동은 인식 성능에는 영향을 미치지 않는다. 하지만 큰 규모의 표적 이동은 객체를 제대로 인식하는데 어려움이 있어 이동 좌표를 합성하여 이런 유형에도 인식할수 있도록 하였다.
크기가 m*n인 이미지 I ∈ Rm×n가 주어지면 이동된 이미지는 다음과 같이 쓰일수 있다.
표적이 이미지 경계를 넘어서지 않도록 보장하기 위해, Guard Window를 사용하였다.
B. Speckling Noise
싱글 룩이라는 가정하에, 관찰된 장면은 다음과 같은 곱셈 노이즈 모델로 모델링 될수 있다. (멀티 룩에서는 여러 개의 독립된 관찰을 평균내어 노이즈를 줄이므로 덧셈 노이즈의 형태를 띈다.)
관찰된 이미지 I에 Mediatn Filter를 적용해 노이즈를 제거한 후 S의 추정치를 구하고 지수 분포에서 무작위 샘플 추출후 각 픽셀의 RCS에 곱해 원본 영상에서 스페클 노이즈가 추가된 새로운 SAR 영상들을 증강한다. 노이즈 지수 분포에서 a를 초과하는 부분을 소거하고 그 분포에 따라 노이즈를 생성하여 노이즈 최대 강도를 조절하였다.
C. Pose Synthesis
방위각 θi를 가진 목표의 기본 이미지 세트 I = {Iθ1 , Iθ2 ,...,IθN }와 목표 방위각 θ∗가 주어졌을 때, θ∗에 가장 근접한 각도를 가진 두 영상을 선택하여 다음과 같은 방식으로 해당 Pose의 영상을 생성한다.
먼저, θ∗에 가장 근접한 각도를 가진 두 이미지 Iθa와 Iθb 를 선택할 때 다음과 같은 식으로 목표 영상을 만든다.
Rθ(I)는 이미지 I를 시계 방향으로 θ도 만큼 회전시키는 작업을 의미하고, CRθ(I)는 이미지 I를 반시계 방향으로 회전시키는 작업을 의미한다. C는 선택된 이미지와 원하는 각도 사이의 차이다.
실험
A. MSTAR 데이터
공개 데이터셋인 BMP2 (보병전투차량), BTR70 (장갑 인원수송차량), T72 (주력 전차) 등 여러 목표물의 0.3 m × 0.3 m 해상도의 X-밴드 SAR 이미지로 구성된 128by128의 MSTAR 데이터셋을 사용하였다. 원래 테스트 데이터 T_Orig 외에 T_Trans와 T_Noise 두 가지 유형의 데이터를 추가로 만들었다. 전자는 각 테스트 이미지를 무작위로 열 번 이동하여 생성하였고, 후자는 각 테스트 이미지에 파라미터 a를 0.5, 0.5, 0.5, 1.0, 1.0, 1.0, 1.5, 1.5, 1.5로 설정하여 아홉 번 노이즈를 추가하여 합성하였다.
B. 단일 증강 학습
ㄱ. Translation 적용 CNN 성능 비교
각 훈련 샘플을 각각 6, 12, 21, 30, 45번 이동시키면서 Guard Window 내에서 무작위 이동시켰다.
T_Orig 에서는 94.29%의 인식 정확도를 달성했고, T_Trans에서는 93.30%를 달성했지만, T_Noise 에서의 비율은 상당히 낮다. Translation 증강으로 훈련된 CNN은 T_Trans 을 처리할 수 있지만 랜덤한 스펙클 노이즈가 적용된 테스트 데이터에서는 표적을 제대로 인식하지 못했다.
ㄴ. Speckle Noising
훈련 세트는 각각 6, 12, 21, 30, 45배로 확장된다. 각 샘플의 노이즈 매개변수 a의 1/3은 0.5로 설정되고, 1/3은 1.0으로, 나머지 1/3은 1.5로 설정했다. Nosing 증강으로 훈련된 CNN은 T_Noise에서 잘 작동하지만, T_Trans에서는 그렇지 않았다.
ㄷ. Pose Synthesis
Pose Synthesis 증강의 효과를 확인하기 위해 각 클래스당 K개의 훈련 샘플을 임의로 선택하여 기본 이미지로 사용하고, 각 클래스당 5000개의 합성 이미지를 생성하였다. T_Orig 원본 테스트 데이터에 대해서는 훈련 샘플 수를 늘릴수록 표적 인식이 향상되었지만 나머지 두 테스트 데이터에는 성능이 좋지 않았다.
ㄹ. 모든 유형의 증강을 결합
모든 세 가지 유형의 증강을 CNN과 결합하여 좀더 공격적인 실험을 수행했다. 각 클래스당 기본 이미지의 수를 120개로 설정하고, 각 클래스당 1000개의 합성 자세 이미지를 생성하였다. 그런 다음, 이들을 무작위로 5번 이동시키고. 마지막으로, 매개변수 a가 0.5, 0.5, 1.0, 1.0, 1.5, 1.5로 설정된 각 이동 이미지에 대해 스페클 노이즈 증강 작업이 수행된다.
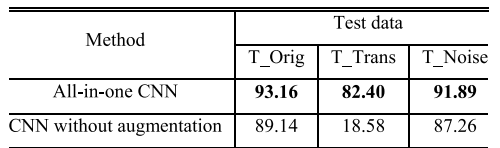
위의 표를 보면 세 가지 조건에 대해서 증강을 수행한 데이터를 학습한 CNN의 경우 원본 테스트 데이터나 이동 합성 데이터, 노이징 합성 데이터에 모두 향상된, 높은 인식 성능을 보였다.
개인적으로 느낀점
위의 결과를 보았을 때, 영상 내 표적의 이동, 다른 강도의 스펙클 노이즈, 표적의 각도, 방향의 변화와 같은 조건에 대해 세 가지 유형의 데이터 증강 수행후 학습시켰을 때 향상된, 효과적인 인식 성능을 보이는 것을 확인할 수 있었다.
우리가 원하는 군사적인 표적이 capture된 SAR 영상은 데이터가 매우 부족하다. 위의 방식을 참고하여 소량의 데이터로부터 위와 같은 증강방법을 도입한다면 어느정도 데이터 확보도 가능할 것 이라고 생각한다. 하지만 동시에 실제 상황에서는 이렇게 가정한 세가지 조건 외에도 어마어마한 변수가 존재할텐데 하나하나마다 증강을 수행해야한다면 학습량이나 증강 데이터를 감당할수 있을지에 대한 의문이 생겼다.
또한 CNN에서의 다중 분류는 softmax 함수와 cross entropy 함수를 사용하므로 주관식이 아닌 객관식 답안지에서 정답을 고르는 것과 같다. 즉 A와 B,C로 학습한 모델에 D를 넣어도 A, B, C 에 해당하는게 없다라고 대답하지 않고 무조건 A,B,C 중에 고른다. 위의 결과에서도 이런 허점이 있을수 있으므로 주관식에 대해서도 답을 할수 있는 딥러닝 모델 구조가 개발될 필요가 있다고 생각한다.
참고문헌
J. Ding, B. Chen, H. Liu and M. Huang, "Convolutional Neural Network With Data Augmentation for SAR Target Recognition," in IEEE Geoscience and Remote Sensing Letters, vol. 13, no. 3, pp. 364-368, March 2016, doi: 10.1109/LGRS.2015.2513754.